VAST Lineage 2009-2018
Four consolidated groups in the VAST dataset:
Description
In the second cases study we took the role of Alice, a VAST Steering Committee (SC) member, who participates in a SC meeting to validate the Program Committee proposed by the VAST paper chairs for the next conference. One of the many problems that all conference organizers face is to balance the members of the Program Committee according to several criteria. The InfoVis Steering Committee Policies FAQ states that the composition of the Program Committee should consider explicitly how to achieve an appropriate and diverse mix of:
- academic lineages
- research topics
- job (academia, industry)
- geography (in rough proportion to the research activity in major regions)
- gender
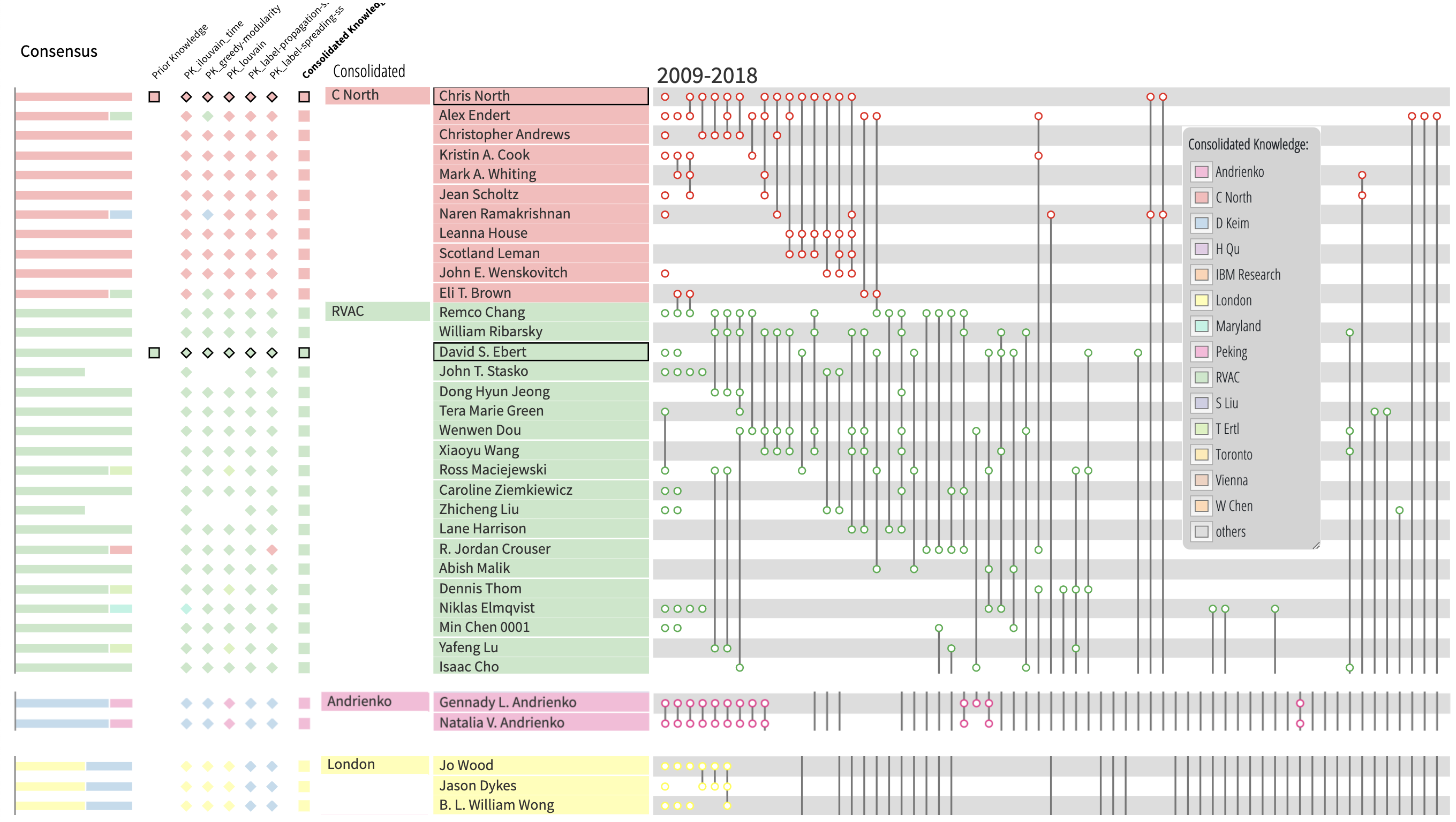
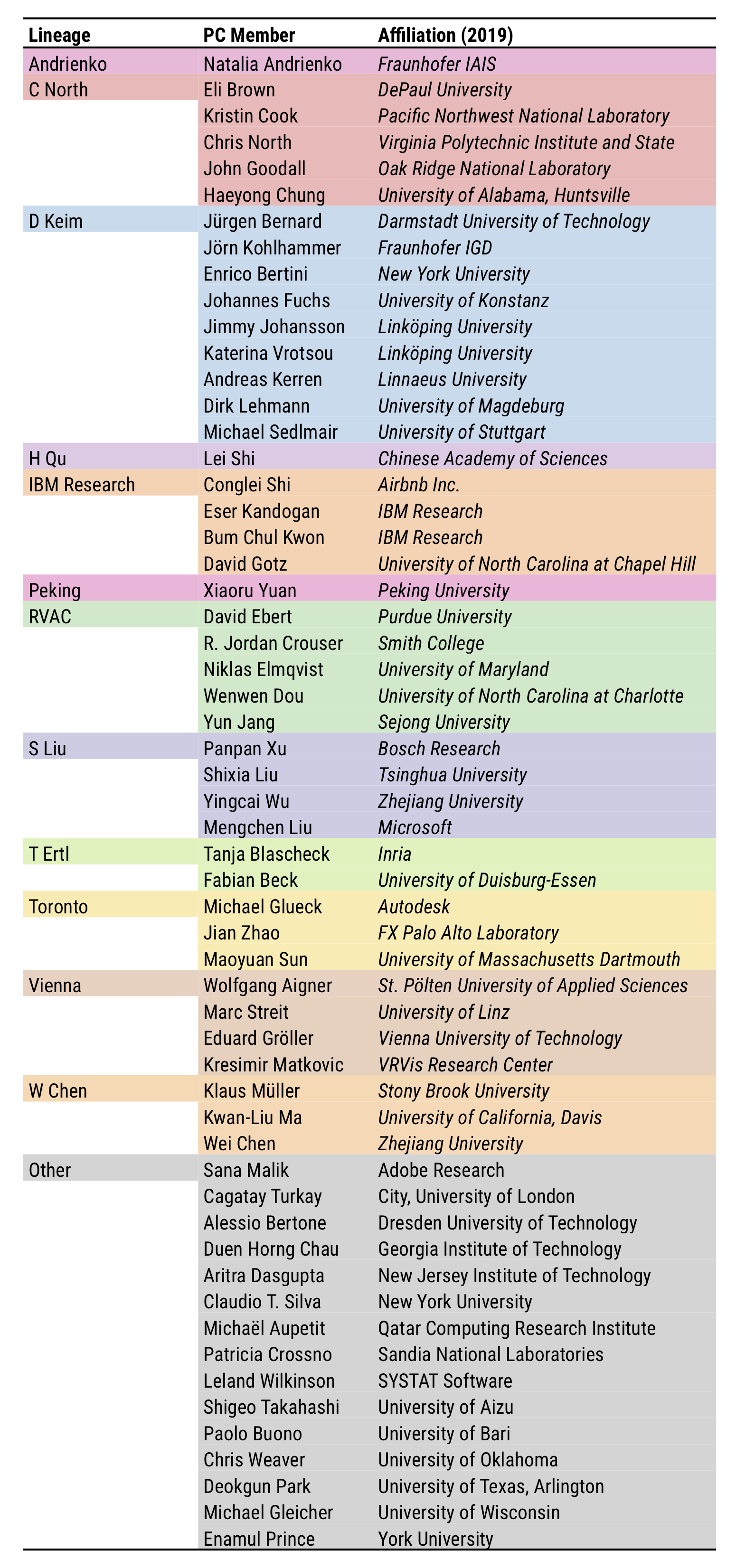
Most of these criteria are well understood, except academic lineage which is not clearly defined. Alice will use the “Visualization Publi- cations Data” (VisPubData) to find-out if she can objectify this concept of lineage to check the diversity of the proposed Program Committee accordingly. Using PK-clustering, Alice loads the VisPubData, filtered to only contain articles from the VAST conference, between 2009–2018. Only prolific authors can be members of the program committee, but highly filtering the co-authorship network would change its structure and disconnect it. Thus, PK-clustering uses the unfiltered network with 1383 nodes to run the clustering and perform the matching (Step 1 of the process). But only 113 authors with more than 4 articles will be consolidated (Steps 2 and 3). Alice then starts the PK-clustering process. She enters her prior knowledge, which is partial and based on two strategies: her knowledge of some areas of VAST, and the name of well-known researchers who have developed their own lineage. She runs the algorithms and 5 algorithms produce a perfect match, acknowledging her knowledge of some areas of VAST. She then shows the results to other members of the SC who will help her consolidating the lineage clusters.
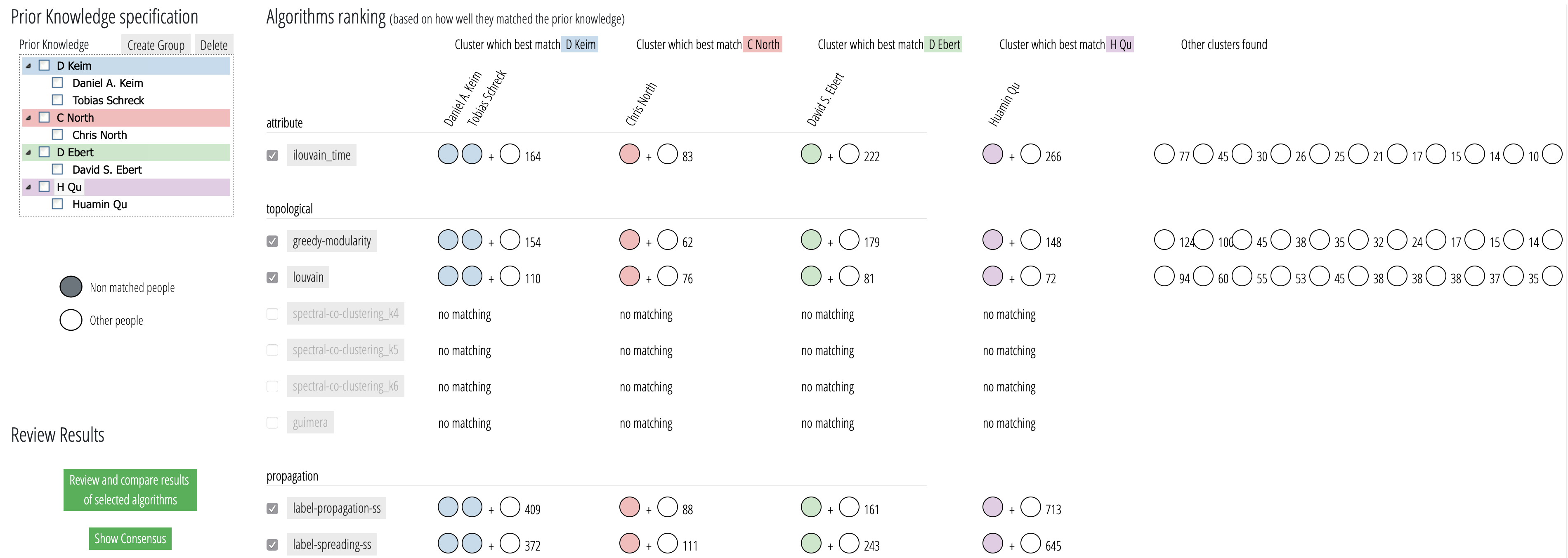
Her initial PK clusters are quickly consolidated, using Internet search to validate some less known authors. She then decides to create as many additional clusters and lineage groups as she can. For some authors, she decides to override the consensus of the algorithms. For example, she decides, and her colleagues agree, that Gennady and Natalia Andrienko are in their own lineage group and not in D. Keim’s. The history of VAST in Europe, very much centered around D. Keim and the VisMaster project, has strongly influenced the network structure and some knowledge is required to untangle it.
Using the louvain algorithm as starting point, Alice creates new groups and achieves a consensus among the experts on a plausible set of lineages for VAST. She then checks with the list proposed by the program committee by entering it in on a spreadsheet with the names and affiliations. She adds the groups and their color, and sort the list by group.

Alice can now report her work to the whole SC, which can check the balance of lineages according to this analysis, and decide if some lineage groups are over or under represented. By keeping the affiliations in the list, the SC can also check the balance of affiliations that is not always aligned with the lineages.
Using partitioning clustering (although with outliers) forces the algorithms or experts to make strong decisions related to lineages. But using a soft clustering (or overlapping partitions), while providing a more nuanced view of lineages, would not be as simple to interpret as coloring spreadsheet lines and sorting them; in the end, the final selection only uses the lineage criteria among many others. Still, we believe PK-clustering can provide a partial but concrete answer to the problem of defining what the scientific lineages are.
Dataset
- Vispubdata: IEEE Visualization (IEEE VIS) publications from 1990-2018.