Bad Stats: Not what it Seems
Transparent statistical communication in HCI research
Pierre Dragicevic and colleagues

| “In the post p<0.05 era, scientific argumentation is not based on whether a p-value is small enough or not. Attention is paid to effect sizes and confidence intervals. Evidence is thought of as being continuous rather than some sort of dichotomy.” Ron Wasserstein, executive director of the American Statistical Association, 2016. |
| We started this page in 2014 to collect arguments and material to help us push back against reviewers who insisted that we should report p-values and declarations of statistical significance. It became a manifesto explaining why it would be beneficial for human-computer interaction and information visualization to move beyond mindless null hypothesis significance testing (NHST), and focus on presenting informative charts with effect sizes and their interval estimates, and drawing nuanced conclusions. Our scientific standards can also be greatly improved by planning analyses and sharing experimental material online. At the bottom of this page you will find studies published at CHI and VIS without any p-value, some of which have received best paper awards. |
👉 2024 update
This web page has not been updated much since 2015, except for the "original material" section below, where we occasionally feature some of our work on statistical communication. Over the past 10 years, I (Pierre) have sightly changed my mind on a few things:
- I'm now more inclined to say that it's OK to report p-values and use them to draw conclusions, as long as they're not used to make dichomotous inferences, i.e., put results in two buckets: significant and non-significant. I remain firmly opposed to such inferences and frustrated by their persistence. My current position is summarized in the introduction of this 2019 paper by Lonni Besançon and myself, which has arguments and many references.
- I'm now also more inclined to accept that it's hard for people not to interpret confidence intervals in a dichotomous way, and perhaps reporting evidence as continuous distributions instead of interval estimates (e.g., reporting posterior probability distributions from Bayesian analyses, as in Matthew Kay's papers) may partly address the problem.
- However, I came to think that the core issues go beyond the distinction between NHST and estimation, and between frequentist and Bayesian statistics:
- People want yes/no answers to research questions. Many authors and readers don't know what to do with nuanced and uncertain conclusions. Many readers are uncomfortable with papers reporting only interval estimates — I can only imagine how uncomfortable they will be with papers reporting only continuous distributions. I expect many paper rejections.
- It's very hard for people to appreciate that the results from any statistical analysis are as unreliable as the data itself. I did a presentation on this topic in 2016.
- Yvonne adds: the issue behind seems to be at least in part a mentality issue. Science is a process and not a machine that produces certainty. We all need to learn to accept that it's so, instead of trying to find new ways to turn stuff into gold. Alchemy's not real and there is no magic way to make scientific data into definitive results. Those who want to reject papers because the results are not definitive (despite the research having been done very rigorously), need to get used to that this is how science works.
- Finally, I came to think that many issues arise from researchers failing to appreciate the importance of distinguishing between planned and unplanned analyses (and thus of pre-registering studies), and that it is really a shame that over 300 journals now accept registered reports as a submission format, but no HCI or VIS journal currently does, as we pointed out in this 2021 paper. One recent exception is the JoVI journal which is a fantastic journal with many desirable characteristics but it is still nascent, and it remains more attractive for students to submit their work to more prestigious venues.
Table of Contents
Original material:
2024 - The Many Ways of Being Transparent in HCI Research (paper)
2021 – Publishing Visualization Studies as Registered Reports (paper)
2021 – Can visualization alleviate dichotomous thinking? (paper)
2020 – Threats of a replication crisis in empirical computer science (paper)
2019 – Explorable multiverse analyses (paper)
2019 – Dichotomous inferences in HCI (paper)
2018 – What are really effect sizes? (blog post)
2018 – My first preregistered study
2018 – Special Interest Group on transparent statistics guidelines (workshop)
2017 – Moving transparent statistics forward (workshop)
2016 – Statistical Dances (keynote)
2016 – Special Interest Group on Transparent Statistics (workshop)
2016 – Fair Statistical Communication in HCI (book chapter)
2014 – Bad Stats are Miscommunicated Stats (keynote)
2014 – Running an HCI Experiment in Multiple Parallel Universes (paper)
External resources:
Quotes about NHST
Links about NHST
Reading List
More Readings
Papers (somehow) in favor of NHST
Papers against confidence intervals
Papers from the HCI Community
Examples of HCI and VIS studies without p-values
Original Material
2024 - The Many Ways of Being Transparent in HCI Research
My colleagues and I have shared a pre-print, The Many Ways of Being Transparent in Human-Computer Interaction Research.
Research transparency has become a common topic of discussion in many fields, including human-computer interaction (HCI). However, constructive discussions require a shared understanding, and the diversity of contribution types and ways of doing research in HCI have made dialog about research transparency difficult. With this paper, we aim to facilitate such dialog by proposing a definition of research transparency that is broadly encompassing to diverse types of HCI research: Research transparency refers to honesty and clarity in all communications about the research processes and outcomes—to the extent possible. We unpack this definition to highlight the different facets of research transparency and offer examples of how transparency can be practiced across different HCI contribution types, including non-empirical contributions. With this article, we argue that research transparency does not have to be inflexible and that transparency in HCI research can be achieved in many ways depending on one’s methodology or contribution type.
2021 - Publishing Visualization Studies as Registered Reports
My colleagues and I have published a paper at alt.VIS 2021, Publishing Visualization Studies as Registered Reports: Expected Benefits and Researchers' Attitudes.
Registered Reports are publications in which study proposals are peer reviewed and pre-accepted before the study is ran. Their adoption in other disciplines has been found to promote research quality and save time and resources. We offer a brief introduction to Registered Reports and their expected benefits for visualization research. We then report on a survey on the attitudes held in the Visualization community towards Registered Reports.
2021 - Can visualization alleviate dichotomous thinking?
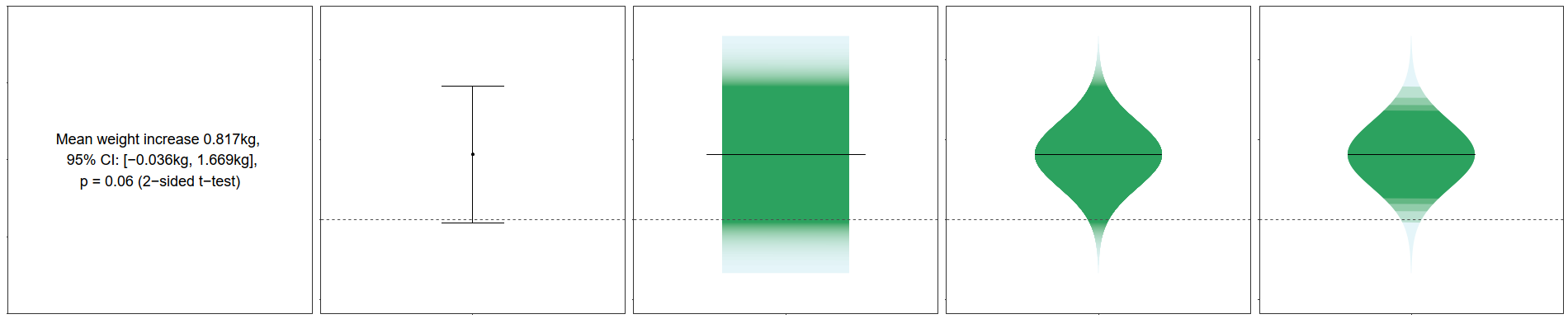
My colleagues Jouni Helske, Satu Helske, Matthew Cooper Anders Ynnerman and Lonni Besançon published a paper in IEEE TVCG Can visualization alleviate dichotomous thinking Effects of visual representations on the cliff effect? They studied whether visualization can alleviate dichotomous thinking of inferential statistics and produce smoother "confidence profiles" over the results. They pfound that, compared to textual representation of p-value and CI, classic CI visualization increased the drop in confidence around the underlying p-value of 0.05. Gradient CI and violin CI, however, produced smaller cliff effect and overall smoother confidence profiles.
- Data Skeptic Podcast episode about the study.
- Our CRAN package to reproduce our visual representations.
- Matthew Kay's CRAN package also provide supports for these visuals.
- Twitter thread about the paper
2020 – Threats of a replication crisis in empirical computer science

Together with Andy Cockburn, Carl Gutwin, and Lonni Besançon, I published a paper on the threats on a replication crisis in empirical computer science and the strategies that can be adopted to mitigate these threats. We found evidence that papers in empirical computer science still rely on binary interpretations of p-values which have been shown to likely lead to a replication crisis. Most of the presented solutions rely on the adoption of more transparency in reporting and embracing more nuanced interpretations of statistical results. We also suggest adopting new publication formats such as registered reports.
2019 – Explorable Multiverse Analyses

We published a paper on explorable multiverse analysis reports, a new approach to statistical reporting where readers of research papers can explore alternative analysis options by interacting with the paper itself.
- Twitter thread summarizing the work: https://twitter.com/mjskay/status/1106742606686494721
- Paper: https://hal.inria.fr/hal-01976951/document
- Github page: https://explorablemultiverse.github.io/
2019 – Dichotomous Inferences in HCI

Lonni Besançon and I published a paper at alt.chi 2019 entitled The Continued Prevalence of Dichotomous Inferences at CHI. We refer to dichotomous inference as the classification of statistical evidence as either sufficient or insufficient. It is most commonly done through null hypothesis significance testing (NHST). Although predominant, dichotomous inferences have proven to cause countless problems. Thus, an increasing number of methodologists have been urging researchers to recognize the continuous nature of statistical evidence and to ban dichotomous inferences. We wanted to see whether they have had any influence on CHI. Our analysis of CHI proceedings from the past nine years suggests that they have not.
In the author version of our paper, we included commentaries from 11 researchers and an authors' response. Commentaries are from Xiaojun Bi, Géry Casiez, Andy Cockburn, Geoff Cumming, Jouni Helske, Jessica Hullman, Matthew Kay, Arnaud Prouzeau, Theophanis Tsandilas, Chat Wacharamanotham, and Shumin Zhai. We are very grateful for their time.
2018 – What are Really Effect Sizes?

In the Transparent Statistics Blog I answer the question Can we call mean differences "effect sizes"?. The answer is yes. In 2020, I wrote a research report A Mean Difference is an Effect Size
2018 – My First Preregistred Study

After four years of planning all my statistical analyses, I'm happy to say that I just conducted my first preregistered study, together with Lonni Besançon, Tobias Isenberg, Ammir Semmo, and collaborators from clinical medicine. The paper title is Reducing Affective Responses to Surgical Images through Color Manipulation and Stylization.
All our R analysis scripts were written ahead of time and tested on simulated data. This made it very easy to preregister our study, as we just had to upload the code and add a few details about planned sample sizes and data exclusion criteria.
2018 – CHI Special Interest Group on Transparent Statistics Guidelines
![]()
With Chat Wacharamanotham, Matthew Kay, Steve Haroz and Shion Guha, I co-organized a CHI SIG titled Special Interest Group on Transparent Statistics Guidelines where we solicited feedback from the HCI community on a first working draft of Transparent Statistics Guidelines and engage potential contributors to push the transparent statistics movement forward.
2017 – CHI Workshop on Moving Transparent Statistics Forward

With Matthew Kay, Steve Haroz, Shion Guha and Chat Wacharamanotham, I co-organized a CHI workshop titled Moving Transparent Statistics Forward as a follow-up to our Special Interest Group on Transparent Statistics. The goal of this workshop was to start developing concrete guidelines for improving statistical practice in HCI. Contact us if you'd like to contribute.
2016 – BioVis Primer Keynote – Statistical Dances
I gave a keynote talk at the BioVis 2016 symposium titled Statistical Dances: Why No Statistical Analysis is Reliable and What To Do About It.
I gave a similar talk in Grenoble in June 2017 that you can watch on the GRICAD website or on Youtube (embedded video above). You can also download the video file (1.82 GB). Thanks to François Bérard and Renaud Blanch for inviting me, and to Arnaud Legrand for organizing this event.
Summary of the Talk: It is now widely recognized that we need to improve the way we report empirical data in our scientific papers. More formal training in statistics is not enough. We also need good "intuition pumps" to develop our statistical thinking skills. In this talk I explore the basic concept of statistical dance. The dance analogy has been used by Geoff Cumming to describe the variability of p-values and confidence intervals across replications. I explain why any statistical analysis and any statistical chart dances across replications. I discuss why most attempts at stabilizing statistical dances (e.g, increasing power or applying binary accept/reject criteria) are either insufficient or misguided. The solution is to embrace the uncertainty and messiness in our data. We need to develop a good intuition of this uncertainty and communicate it faithfully to our peers. I give tips for conveying and interpreting interval estimates in our papers in a honest and truthful way.
- Video of the talk (Grenoble version). © GRICAD.
- Watch the slides on your Web browser (with animations)
- Watch the collective dance on youtube
 Download the slides (PDF 5MB)
Download the slides (PDF 5MB)
- Download the videos from the slides (ZIP 3.5MB)
- Bibliography for the talk.
Animated plots by Pierre Dragicevic and Yvonne Jansen.
Erratum: In the video linked above I said we need to square sample size to get dances twice as small. I should have said that we need to multiply sample size by four.
2016 – CHI Special Interest Group on Transparent Statistics in HCI
![]()
With Matthew Kay, Steve Haroz and Shion Guha, I co-organized a SIG meeting at CHI '16 titled Transparent Statistics in HCI. We propose to define transparent statistics as a philosophy of statistical reporting whose purpose is scientific advancement rather than persuasion. The meeting generated lots of interest and we are now looking at forming a community and developing some concrete recommendations to move the field forward. If you are interested, join our mailing list.
2016 – Book Chapter: Fair Statistical Communication in HCI

I wrote a book chapter titled Fair Statistical Communication in HCI that attempts to explain why and how we can do stats without p-values in HCI and Vis. The book is titled Modern Statistical Methods for HCI and is edited by Judy Robertson and Maurits Kaptein. I previously released an early draft as a research report titled HCI Statistics without p-values. However, I recommend that you use the Springer chapter instead (pre-print link below), as it's more up-to-date and much improved.
Get the final book chapter from Springer
Download author version (PDF 1.8 MB)
See errata, updated tips, and responses.
2014 – BELIV Keynote: Bad Stats are Miscommunicated Stats
I gave a keynote talk at the BELIV 2014 bi-annual workshop entitled Bad Stats are Miscommunicated Stats.
Summary of the talk: When reporting on user studies, we often need to do stats. But many of us have little training in statistics, and we are just as anxious about doing it right as we are eager to incriminate others for any flaw we might spot. Violations of statistical assumptions, too small samples, uncorrected multiple comparisons—deadly sins abound. But our obsession with flaw-spotting in statistical procedures makes us miss far more serious issues and the real purpose of statistics. Stats are here to help us communicate about our experimental results for the purpose of advancing scientific knowledge. Science is a cumulative and collective enterprise, so miscommunication, confusion and obfuscation are much more damaging than moderately inflated Type I error rates.
In my talk, I argue that the most common form of bad stats are miscommunicated stats. I also explain why we all have been faring terribly according to this criteria—mostly due to our blind endorsement of the concept of statistical significance. This idea promotes a form of dichotomous thinking that not only gives a highly misleading view of the uncertainty in our data, but also encourages questionable practices such as selective data analysis and various other forms of convolutions to reach the sacred .05 level. While researchers’ reliance on mechanical statistical testing rituals is both deeply entrenched and severely criticized in a range of disciplines—and has been so for more than 50 years—it is particularly striking that it has been so easily endorsed by our community. We repeatedly stress the crucial role of human judgment when analyzing data, but do the opposite when we conduct or review statistical analyses from user experiments. I believe that we can cure our schizophrenia and substantially improve our scientific production by banning p-values, by reporting empirical data using clear figures with effect sizes and confidence intervals, and by learning to provide nuanced interpretations of our results. We can also dramatically raise our scientific standards by pre-specifying our analyses, fully disclosing our results, and sharing extensive replication material online. These are small but important reforms that are much more likely to improve science than methodological nitpicking on statistical testing procedures.
Download the slides (PDF 3MB) 2014 – Alt.CHI Paper: Running an HCI Experiment in Multiple Parallel Universes

Pierre Dragicevic, Fanny Chevalier and Stéphane Huot (2014) Running an HCI Experiment in Multiple Parallel Universes. In ACM CHI Conference on Human Factors in Computing Systems (alt.chi). Toronto, Canada, Apr, Apr 2014.
The purpose of this alt.chi paper was to raise the community's awareness on the need to question the statistical procedures we currently use to interpret and communicate our experiment results, i.e., the ritual of null hypothesis significance testing (NHST). The paper does not elaborate on the numerous problems of NHST, nor does it discuss how statistics should be ideally done, as these points have been already covered in hundreds of articles published across decades in many disciplines. The interested reader can find a non-exhaustive list of references below.
A comment often elicited by this paper is that HCI researchers should learn to use NHST properly, or that they should use larger sample sizes. This is not the point we are trying to make. Also, we are not implying that we should reject inferential statistics altogether, or that we should stop caring about statistical error. See the discussion thread from the alt.chi open review process. Our personal position is that HCI research can and should get rid of NHST procedures and p-values, and instead switch to reporting (preferably unstandardized) effect sizes with interval estimates — e.g., 95% confidence intervals — as recommended by many methodologists.
Download the slides (PDF 5MB) In our presentation we take an HCI perspective to rebut common arguments against the discontinuation of NHST, namely: i) the problem is NHST misuse, ii) the problem is low statistical power, iii) NHST is needed to test hypotheses or make decisions, iv) p-values and confidence intervals are equivalent anyways, v) we need both.
Quotes About Null Hypothesis Significance Testing (NHST)
The number of papers papers stressing the deep flaws of NHST is simply bewildering. Sadly, the awareness of this literature seems very low in HCI and Infovis. Yet most criticisms are not about the theoretical underpinnings of NHST, but about its usability. Will HCI and Infovis give the good example to other disciplines?
| “...no scientific worker has a fixed level of significance at which from year to year, and in all circumstances, he rejects hypotheses; he rather gives his mind to each particular case in the light of his evidence and his ideas.” Sir Ronald A. Fisher (1956), quoted by Gigerenzer (2004). |
| “[NHST] is based upon a fundamental misunderstanding of the nature of rational inference, and is seldom if ever appropriate to the aims of scientific research.” Rozeboom (1960), quoted by Levine et al. (2008) |
| “Statistical significance is perhaps the least important attribute of a good experiment; it is never a sufficient condition for claiming that a theory has been usefully corroborated, that a meaningful empirical fact has been established, or that an experimental report ought to be published.” Likken (1968), quoted by Levine et al. (2008) |
| “Small wonder that students have trouble [learning significance testing]. They may be trying to think.” Deming (1975), quoted by Ziliak and McCloskey (2009) |
| “I believe that the almost exclusive reliance on merely refuting the null hypothesis as the standard method for corroborating substantive theories is a terrible mistake, is basically unsound, poor scientific strategy, and one of the worst things that ever happened in the history of psychology. I am not making some nit-picking statistician’s correction. I am saying that the whole business is so radically defective as to be scientifically almost pointless.” Paul Meehl (1978), quoted by Levine et al. (2008) |
| “One of the most frustrating aspects of the journal business is the null hypothesis. It just will not go away. [...]. It is almost impossible to drag authors away from their p values [...]. It is not uncommon for over half the space in a results section to be composed of parentheses inside of which are test statistics, degrees of freedom, and p values. Perhaps p values are like mosquitos. They have an evolutionary niche somewhere and no amount of scratching, swatting, or spraying will dislodge them.” John Campbell (1982) |
| “After 4 decades of severe criticism, the ritual of null hypothesis significance testing -- mechanical dichotomous decisions around a sacred .05 criterion -- still persists.” Jacob Cohen (1994) |
| “Statistical significance testing retards the growth of scientific knowledge; it never makes a positive contribution.” Schmidt and Hunter (1997) |
| “Logically and conceptually, the use of statistical significance testing in the analysis of research data has been thoroughly discredited.” Schmidt and Hunter (1997), quoted by Levine et al. (2008) |
| “D. Anderson, Burnham and W.Thompson (2000) recently found more than 300 articles in different disciplines about the indiscriminate use of NHST, and W. Thompson (2001) lists more than 400 references on this topic. [...] After review of the debate about NHST, I argue that the criticisms have sufficient merit to support the minimization or elimination of NHST.” Rex B Kline (2004) |
| “Our unfortunate historical commitment to significance tests forces us to rephrase good questions in the negative, attempt to reject those nullities, and be left with nothing we can logically say about the questions.” Killen (2005), quoted by Levine et al. (2008) |
| “If these arguments are sound, then the continuing popularity of significance tests in our peer-reviewed journals is at best embarrassing and at worst intellectually dishonest.” Lambdin (2012) |
| “Many scientific disciplines either do not understand how seriously weird, deficient, and damaging is their reliance on null hypothesis significance testing (NHST), or they are in a state of denial.” Geoff Cumming, in his open review of our alt.chi paper |
| “A ritual is a collective or solemn ceremony consisting of actions performed in a prescribed order. It typically involves sacred numbers or colors, delusions to avoid thinking about why one is performing the actions, and fear of being punished if one stops doing so. The null ritual contains all these features.” Gerd Gigerenzer, 2015 |
| “The widespread use of “statistical significance” (generally interpreted as “p ≤ 0.05”) as a license for making a claim of a scientific finding (or implied truth) leads to considerable distortion of the scientific process.” The American Statistical Association, 2016 |
Links
Note: the material and references that follow are generally older than 2015. A lot has been written since then and I also came across a lot more interesting stuff, particularly on pre-registration and registered reports. I haven't found the courage to update the lists, but the papers below are still worthwhile a read.
To learn more about issues with NHST and how they can be easily addressed with interval estimates, here are two good starting points that will only take 25 minutes of your time in total.
- (Cumming, 2011) Significant Does not Equal Important: Why we Need the New Statistics (radio interview).
A short podcast accessible to a wide audience. Focuses on the understandability of p values vs. confidence intervals. In an ideal world, this argument alone should suffice to convince people to whom usability matters. - (Cumming, 2013) The Dance of p values (video).
A nice video demonstrating how unreliable p values are across replications. Methodologist and statistical cognition researcher Geoff Cumming has communicated a lot on this particular problem, although many other problems have been covered in previous literature (references below). An older version of this video was the main source of inspiration for our alt.chi paper..
Reading List
Those are suggested initial readings. They are often quite accessible and provide a good coverage of the problems with NHST, as well as their solutions.
- (Cohen, 1994) The Earth is Round (p < 0.05).
Perhaps the most famous paper criticizing NHST. - (Loftus, 1993) A picture is worth a thousand p values: On the irrelevance of hypothesis testing in the microcomputer age.
Argues for using figures with means and standard errors (or CIs) instead of NHST. Illustrates with two nice examples. - (Schmidt and Hunter, 1997) Eight common but false objections to the discontinuation of significance testing in the analysis of research data.
Rebuts common arguments for keeping NHST. Among other things, explains why increasing sample size and power will not work as a solution, why educating researchers to minimize NHST misuse won't work either, and why dichotomous accept/reject hypothesis testing is futile. Recommends to use confidence intervals instead and to emphasize meta-analysis. This is a very convincing paper but be warned that it is sometimes quoted as making excessive claims. - (Lambdin, 2012) Significance tests as sorcery: Science is empirical—significance tests are not.
Another strong criticism of NHST. Summarizes arguments against NHST very nicely, and provides many references. - (Giner-Sorolla, 2012). Science or art? How aesthetic standards grease the way through the publication bottleneck but undermine science.
An excellent paper that explains how the publication system forces us to trade off good science for nice stories. - (Cumming and Finch, 2005) Inference by Eye: Confidence Intervals and How to Read Pictures of Data.
Clarifies how to read confidence intervals and their equivalence with NHST. - (Cumming, 2014) The New Statistics: Why and How.
Covers many topics on how to do good empirical research. Highly recommended as a general reference. The proposed guidelines have been recently adopted by the editorial committee of the Psychological Science Journal. - (Cumming and Calin-Jageman, 2016) Introduction to the New Statistics: Estimation, Open Science, and Beyond.
The first introductory statistics textbook to use an estimation approach from the start. Also discusses open science and explains NHST so that students can understand published research. Very easy to read, and with plenty of exercises. - (Amrhein, Greenland, and McShane, 2019) Scientists rise up against statistical significance.
One of the most shared ever paper online that criticises NHST and binary readings. Has been co-signed by more than 800 scientists - (Halsey, 2019) The reign of the p-value is over: what alternative analyses could we employ to fill the power vacuum?
- (Michel et al.), New Author Guidelines for Displaying Data and Reporting Data Analysis and Statistical Methods in Experimental Biology
A paper giving guidelines on experiment reporting, pre-registration, inferences on statistical results...
More Readings
List not maintained and basically not updated since 2015.
Other references, some of which are rather accessible while others may be a bit technical for non-statisticians like most of us. Best is to skip the difficult parts and return to the paper later on. I have plenty of other references that I won't have time to add here, for more see my book chapter.
- (Kline, 2004) What's Wrong With Statistical Tests--And Where We Go From Here.
A broad overview of the problems of NHST and publications questioning significance testing (~300 since 1950s). Recommends to downplay or eliminate NHST, report effect sizes with confidence intervals instead, and focus on replication.  (Amrhein et al, 2017) The earth is flat (p>0.05): Significance thresholds and the crisis of unreplicable research.
(Amrhein et al, 2017) The earth is flat (p>0.05): Significance thresholds and the crisis of unreplicable research.
An up-to-date and exhaustive review of arguments against the use of a significance threshold with p-values. The authors are not for banning p-values, but provide a very strong and convincing critique of binary significance, with many references. Still at the pre-print stage.- (Gigerenzer, 2004) Mindless statistics.
Another (better) version of Gigerenzer's paper The Null Ritual - What You Always Wanted to Know About Significance Testing but Were Afraid to Ask. Explains why the NHST ritual is a confusing combination of Fisher and Neyman/Pearson methods. Explains why few people understand p, problems with meaningless nil hypotheses, problems with the use of "post-hoc alpha values", pressures on students by researchers, researchers by editors, etc. Important paper although not a very easy read. - (Ziliak and McCloskey, 2009) The Cult of Statistical Significance.
A harsh criticism of NHST, from the authors of the book "The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives ". Nicely explains why effect size is more important than precision (which refers to both p values and widths of confidence intervals). - (Gelman, 2013) Interrogating p-values.
Explains towards the end why p-values are inappropriate even for making decisions, and that effect sizes should be used instead. - (Cumming, 2008) p Values Predict the Future Only Vaguely, but Confidence Intervals Do Much Better.
Examines the unreliability of p values and introduces p intervals. For example, when one obtains p = .05, there is a 80% chance that the next replication yields p inside [.00008, .44], and a 20% chance it's outside.
Effect size
Effect size does not mean complex statistics. If you report mean task completion times, or differences in mean task completion times, you're reporting effect sizes.
- (Baguley, 2009). Standardized or simple effect size: What should be reported?
Explains why it is often preferable to report effect sizes in the original units rather than computing standardized effect sizes like Cohen's d. - (Dragicevic, 2012). My Technique is 20% Faster: Problems with Reports of Speed Improvements in HCI.
Explains why terms such as "20% faster" are confusing.
Bootstrapping
Bootstrapping is an easy method for computing confidence intervals for many kinds of distributions. It's too computationally intensive to have been even conceivable in the past, but now we have this thing called a computer. Oh, and it's non-deterministic — if this disturbs you, then maybe take another look at our alt.chi paper!
- went offline Confidence Intervals Using Bootstrapping: Statistics Help (video).
A video explaining bootstrapping. - went offline Confidence intervals for the mean using bootstrapping.
Short explanation on how to compute bootstrap CIs in R (provides several methods). - BootES: An R Package for Bootstrap Confidence Intervals on Effect Sizes
A scientific article introducing a powerful R package for computing all sorts of CIs. Discusses the theoretical support behind bootstrapping while remaining very accessible (for a psychology audience). Advocates the use of contrasts instead of ANOVAs.
Statistical errors
In addition to having been greatly over-emphasized, the notion of type I error is misleading. One issue is that the nil hypothesis of no effect is almost always false, so it's practically impossible to commit a type I error. At the same time, many NHST critics stress the absurdity of testing nil hypotheses, but this is rarely what people (especially in HCI) are really doing. Some articles on this page clarify this, here are more articles specifically on the topic of statistical errors. More to come.
- (Gelman, 2004) Type 1, type 2, type S, and type M errors (Blog bost).
Coins type S errors (errors of sign) and type M errors (errors of magnitude). Points to an article that is more technical. - (Pollard, 1987) On the Probability of Making Type I Errors.
Explains why the alpha level does not give you the probability of making a type I error.
Multiple comparisons
How to deal with multiple comparisons? Use a simple experiment design, pick meaningful comparisons in advance, and use interval estimates.
- (Perneger, 1998) What’s wrong with Bonferroni adjustments.
Adjustment procedures for multiple comparisons is not uncontroversial. One issue is that they dramatically inflate type II errors. This author recommends to simply report what we analyzed and why, and rely on our (and our readers') judgment. This judgment is naturally greatly facilitated by the use of an estimation approach. - (Smith et al., 2002) The High Cost of Complexity in Experimental Design and Data Analysis -- Type I and Type II Error Rates in Multiway ANOVA.
This paper complements the one above: to avoid the problem of multiple comparisons, best is to design simpler experiments and decide on what is worth comparing. Related to pre-specification of analyses (Cumming, 2014) and to contrast analysis.
Contrast analysis
Still looking for an accessible introduction. Suggestions welcome.
Hypotheses
HCI is a young field and rarely has deep hypotheses to test. If you only have superficial research questions, frame them in a quantitative manner (e.g., is my technique better and if so, to what extent?) and answer them using estimation. If you have something deeper to test, be careful how you do it. It's hard.
- (Meehl, 1967) Theory-testing in Psychology and Physics: A Methodological Paradox.
Contrasts substantive theories with statistical hypotheses, and explains why testing the latter provides only a very weak confirmation of the former. Also clarifies that point nil hypotheses in NHST are really used for testing directional hypotheses (see also section 'Errors' above). Paul Meehl is an influential methodologist and has written other important papers, but his style is a bit dry. I will try to add more references from him on this page later on.
Bayesian statistics
- (Kruschke, 2010) Doing Bayesian Data Analysis: A Tutorial with R and BUGS.
This book has been recommended to me several times as being an accessible introduction to Bayesian methods, although I did not read it yet. If you are willing to invest time, Bayesian (credible) intervals are worth studying as they have several advantages over confidence intervals. - (McElreath, 2015) Statistical Rethinking.
This book is recommended by Matthew Kay for its very accessible introduction to Bayesian analysis. Pick this one or Kruschke's. - (Kruschke and Liddell, 2015) The Bayesian New Statistics: Two historical trends converge.
Explains why estimation (rather than null hypothesis testing) and Bayesian (rather than frequentist) methods are complementary, and why we should do both.
Other papers cited in the BELIV talk
- (Dawkins, 2011) The Tyranny of the Discontinuous Mind.
A short but insightful article by Richard Dawkins that explains why dichotomous thinking, or more generally categorical thinking, can be problematic. - (Rosenthal and Gaito, 1964) Further evidence for the cliff effect in interpretation of levels of significance.
A short summary of early research in statistical cognition showing that people trust p-values that are sightly below 0.05 much more than p-values that are slightly above. This seems to imply that Fisher's suggestion to minimize the use of decision cut-offs and simply report p-values as a measure of strength of evidence may not work.
Papers (somehow) in favor of NHST
List not maintained and basically not updated since 2015.
To fight confirmation bias here is an attempt to provide credible references that go against the discontinuation of NHST. Many are valuable in that they clarify what NHST is really about.
- (Abelson, 1995) Statistics as Principled Argument (Chapter 1).
A book lauded by (Cairns, 2007) below. The link points to a free version of the first chapter. Focuses on arguments and story that stats serve to build. Acknowledges that NHST is only a starting point (book was reviewed by Jacob Cohen). Quite interesting and insightful. - (Abelson, 1997) A Retrospective on the Significance Test Ban of 1999 (If There Were no Significance Tests, they Would be Invented).
This paper wants to be in defense of NHST, and uses a dystopic scenario to achieve this (1999 is after the article publication). Both the presentation of NHST (which clarifies that NHST typically serves to test directional, not nil hypotheses) and the discussion of its misuses are excellent. However, the defense of NHST is rather unconvincing: if confidence intervals must be provided, then it is not clear why p-values should be kept. - (Levine et al, 2008) A Critical Assessment of Null Hypothesis Significance Testing in Quantitative Communication Research.
Although this paper's focus is on summarizing known issues with NHST, it is not against its discontinuation. It contains a very good paragraph summarizing NHST. - (Levine et al, 2008) A Communication Researchers' Guide to Null Hypothesis Significance Testing and Alternatives.
The companion article of the reference above. Again, says NHST should be complemented with effect size estimates and confidence intervals, but does not explain why NHST should be kept. Discusses "effect tests" and equivalence testing.
Papers against confidence intervals
List not maintained and basically not updated since 2015.
For several decades Bayesians have (more or less strongly) objected to the use of confidence intervals, but their claim that "CIs don't solve the problems of NHST" is misleading. Confidence intervals and credible (Bayesian) intervals are both interval estimates, thus a great step forward compared to dichotomous testing. Credible intervals arguably rest on more solid theoretical foundations and have a number of advantages, but they also have a higher switching cost. By claiming that confidence intervals are invalid and should never be used, Bayesian idealists may just give NHST users an excuse for sticking to their ritual.
- (Morey et al, in press) The Fallacy of Placing Confidence in Confidence Intervals.
This is the most recent paper on the topic, with many authors and with the boldest claims. It is very informative and shows that CIs can behave in pathological ways in specific situations. Unfortunately, it is hard to assess the real consequences, i.e., how much we are off when we interpret CIs as ranges of plausible parameter values in typical HCI user studies. Also see this long discussion thread on an older revision, especially toward the end.
Papers from the HCI Community
List not maintained and basically not updated since 2015.
There has been several papers in HCI questioning current practices, although (until recently) none of them calls for a discontinuation or even minimization of NHST, none of them mentions the poor replicability of p-values, and no satisfactory treatment of interval estimation is provided.
- (Cairns, 2007) HCI... not as it should be: inferential statistics in HCI research
A good summary of sloppy use of NHST methods in HCI, with a nice explanation of NHST in the introduction and an interesting discussion at the end. Overall in favor of NHST but duly acknowledges that it is not the only method. - (Wilson et al, 2011) RepliCHI -- CHI should be replicating and validating results more.
The CHI workshop on replication that started the repliCHI initiative. Replication is important, and as explained in (Cumming, 2012), estimation promotes replication and makes meta-analyses possible. NHST does neither. I have been told that the RepliCHI initiative has been discontinued. - (Robertson, 2011) Stats: We're Doing It Wrong (blog post).
Covers problems related to statistical assumptions and the need to report effect size, although it does not discuss deeper problems with NHST. - (Kaptein and Robertson, 2012) Rethinking statistical analysis methods for CHI.
Reviews a few common problems with NHST, but does not cover how some of these issues can be addressed by taking an estimation approach. - (Hornbaek et al, 2014) Is Once Enough? On the Extent and Content of Replications in Human-Computer Interaction.
Helpfully clarifies what a replication is in HCI, what it is good for, and to what extent it has been used in the past.
Examples of HCI and VIS studies without p-values
- 2014 theses
- Yvonne Jansen's PhD thesis Physical and Tangible Information Visualization analyzes all experimental data using estimation (Chapters 5 and 6). The PhD thesis has no single p-value and has received an honorable mention at the Gilles Kahn PhD thesis awards.
- VIS 2014
- The study by Chevalier, Dragicevic and Franconeri The Not So Staggering Effect of Staggered Animations makes no use of p-values, separates planned from exploratory analyses, and has a page with extensive replication material.
- The study by Talbot, Setlur, and Anand Four Experiments on the Perception of Bar Charts makes no use of p-values and has replication material online. Their paper replicates a well-known 1984 study by Cleveland and McGill that also used estimation exclusively. Cleveland and McGill used bootstrap confidence intervals only a few years after Efron introduced them!
- CHI 2015
- The study by Willett, Jenny, Isenberg and Dragicevic Lightweight Relief Shearing for Enhanced Terrain Perception on Interactive Maps has received a best paper award despite having not a single p-value. It has replication material online.
- The study by Wacharamanotham, Subramanian, Volkel and Borchers Statsplorer: Guiding Novices in Statistical Analysis also bases all of its analyses on confidence intervals and has no p-value.
- The study by Goffin, Bezerianos, Willett and Isenberg (published as an extended abstract) Exploring the Effect of Word-Scale Visualizations on Reading Behavior uses estimation and plots instead of p-values.
- VIS 2015
- The study by Yu, Efstathiou, Isenberg and Isenberg CAST: Effective and Efficient User Interaction for Context-Aware Selection in 3D Particle Clouds also has no p-value.
- The study by Jansen and Hornbæk A Psychophysical Investigation of Size as a Physical Variable has no p-value and shares replication/reanalysis material online.
- The study by Kay and Heer Beyond Weber’s Law: A Second Look at Ranking Visualizations of Correlation uses Bayesian estimation and only has a single p-value. All analyses are available online. The paper has received a best paper honorable mention award.
- The study by Boy, Eveillard, Detienne and Fekete Suggested Interactivity: Seeking Perceived Affordances for Information Visualization has no p-value either.
- 2016 theses
- Chat Wacharamanotham's PhD thesis Drifts, Slips, and Misses: Input Accuracy for Touch Surfaces re-analyzes all its published studies using an estimation paradigm. It discusses the differences with NHST.
- Oleksandr Zinenko's PhD thesis Interactive Program Restructuring analyzes all experimental data using estimation, and has an appendix explaining and justifying the statistical methods used.
- CHI 2016
- The study by Zhao, Glueck, Chevalier, Wu and Khan Egocentric Analysis of Dynamic Networks with EgoLines uses estimation and descriptive statistics (no p-value), and has received a best paper honorable mention award.
- The study by Matejka, Glueck, Grossman, and Fitzmaurice The Effect of Visual Appearance on the Performance of Continuous Sliders and Visual Analogue Scales uses estimation only and has received a best paper award.
- The study by Asenov, Hilliges and Müller The Effect of Richer Visualizations on Code Comprehension also has no p-value.
- GI 2016
- The study by Thudt, Walny, Perin, Rajabiyazdi, MacDonald, Vardeleon, Greenberg, and Carpendale Assessing the Readability of Stacked Graphs reports all results using estimation.
- CG&A 2016
- The study by Perin, Boy and Vernier Using Gap Charts to Visualize the Temporal Evolution of Ranks and Scores reports all results using estimation.
- AVI 2016
- The study by Le Goc, Dragicevic, Huron, Boy, and Fekete A Better Grasp on Pictures Under Glass: Comparing Touch and Tangible Object Manipulation using Physical Proxies reports its results using estimation.
- VIS 2016
- The study by Dimara, Bezerianos and Dragicevic The Attraction Effect in Information Visualization uses estimation only and received a best paper honorable mention award. It uses planned analyses, shares experimental material online, and has a companion paper with negative results.
- The study by Haroz, Kosara and Franconeri The Connected Scatterplot for Presenting Paired Time Series reports all quantitative analyses using confidence intervals.
- 2017 theses
- Julie Ducasse's PhD thesis Tabletop tangible maps and diagrams for visually impaired users analyzes all of its studies using estimation and reports no single p-value.
- Lonni Besançon's PhD thesis An interaction Continuum for 3D Dataset Visualization analyzes all of its studies using estimation technique and does not report p-values. Additionally, it presents an appendix justifying for the use of estimation techniques instead of the classical dichotomous interpretation.
- CHI 2017
- The study by Dimara, Bezerianos and Dragicevic Narratives in Crowdsourced Evaluation of Visualizations: A Double-Edged Sword? has no p-value and has experimental material online.
- The study by Besançon, Issartel, Ammi and Isenberg Mouse, Tactile, and Tangible Input for 3D Manipulation makes no use of p-values and uses plots with confidence intervals instead.
- The study by Besançon, Ammi and Isenberg Pressure-Based Gain Factor Control for Mobile 3D Interaction using Locally-Coupled Devices makes no use of p-values and uses plots with confidence intervals instead. It received a best paper honorable mention award.
- The study by Boy, Pandey, Emerson, Satterthwaite, Nov, and Bertini Showing People Behind Data: Does Anthropomorphizing Visualizations Elicit More Empathy for Human Rights Data? reports its results using confidence intervals.
- IHM 2017
- Emmanuel Dubois and Marcos Serrano published three studies using estimation only at the French-speaking HCI conference IHM 2017. One study co-authored with Perelman, Picard, and Derras received the best paper award. The other two studies were co-authored by Raynal, and by Cabric.
- VIS 2017
- The study by Walny, Huron, Perin, Wun, Pusch, and Carpendale Active Reading of Visualizations uses planned analyses, reports all results using estimation and has experimental material online.
- The study by Dragicevic and Jansen Blinded with Science or Informed by Charts? A Replication Study uses planned analyses, reports all results using estimation and has experimental material online.
- The study by Perin, Wun, Pusch, and Carpendale Assessing the Graphical Perception of Time and Speed on 2D+Time Trajectories uses planned analyses, reports all results using estimation and has experimental material online.
- The study by Hullman, Kay, Kim, and Shrestha Imagining Replications: Graphical Prediction & Discrete Visualizations Improve Recall & Estimation of Effect Uncertainty reports all results using Bayesian estimation and has experimental material online.
- The study by Felix, Bertini, and Franconeri Taking Word Clouds Apart: An Empirical Investigation of the Design Space for Keyword Summaries uses planned analyses and reports all results using estimation.
- The study by Dimara, Bezerianos and Dragicevic Conceptual and Methodological Issues in Evaluating Multidimensional Visualizations for Decision Support uses planned analyses and reports all results using estimation.
- The study by Wang, Chu, Bao, Zhu, Deussen, Chen, and Sedlmair EdWordle: Consistency-preserving Word Cloud Editing reports its results using estimation.
- The study by Valdez, Ziefle, and Sedlmair Priming and Anchoring Effects in Visualization reports most of its results using estimation.
- SUI 2017
- The study by Li, Willett, Sharlin and Costa Sousa Visibility Perception and Dynamic Viewsheds for Topographic Maps and Models reports all of its results using estimation.
- CHI 2018
- The study by Jansen and Hornbæk How Relevant are Incidental Power Poses for HCI? reports all its results using estimation, has experimental material online, and received a best paper award.
- The study by Fernandes, Walls, Munson, Hullman and Kay Uncertainty Displays Using Quantile Dotplots or CDFs Improve Transit Decision-Making reports all its results using estimation, uses partly pre-registered analyses, has experimental material online, and received a honorable mention award.
- The study by Feng, Deng, Peck and Harrison The Effects of Adding Search Functionality to Interactive Visualizations on the Web reports all results using estimation and has experimental material online.
- Expressive 2018
- The study by Besançon, Semmo, Biau, Frachet, Pineau, Sariali, Taouachi, Isenberg, and Dragicevic Reducing Affective Responses to Surgical Images through Color Manipulation and Stylization reports all results using estimation, has a pre-registered experiment and has all experimental material online.
- VIS 2018
- [In progress]
- The study from Brehmer et al. Visualizing Ranges over Time on Mobile Phones: A Task-Based Crowdsourced Evaluation reports results with estimation techniques.
- The study from Gogolou, Tsandilas, Palpanas, and Bezerianos Comparing Similarity Perception in Time Series Visualizations is based on interval estimation.
- CHI 2019
- None of these papers reports p-values in their statistical analysis:
- Caitlin Kuhlman et al. Evaluating Preference Collection Methods for Interactive Ranking Analytics
- Pranathi Mylavarapu et al. Ranked-List Visualization: A Graphical Perception Study
- Florine Simon et al. Finding Information on Non-Rectangular Interfaces
- Ruta Desai et al. Geppeto: Enabling Semantic Design of Expressive Robot Behaviors
- Yvonne Jansen et al. Effects of Locomotion and Visual Overview on Spatial Memory when Interacting with Wall Displays
- Kurtis Danyluk et al. Look-From Camera Control for 3D Terrain Maps
- EuroVIS 2019
- Wang et al. in Augmenting Tactile 3D Data Navigation With Pressure Sensing reports results using estimation.
- Besançon et al. in Hybrid Touch/Tangible Spatial 3D Data Selection report results using estimation.
- CHI 2021
- Saidi et al. in HoloBar: Rapid Command Execution for Head-Worn AR Exploiting Around the Field-of-View Interaction reports results using estimation.
- Keddisseh et al. in KeyTch: Combining the Keyboard with a Touchscreen for Rapid Command Selection on Toolbars reports results using estimation.
- EuroVIS 2021
- Svicarovic1 et al. in Evaluating Interactive Comparison Techniques in a Multiclass Density Map for Visual Crime Analytics report results using bootstrap confidence intervals.
- Contact us if you know of more papers. We'll be happy to add yours! Make sure the PDF is available online and not behind a paywall.
The papers we co-author are by no means prescriptive. We are still polishing our methods and learning. We are grateful to Geoff Cumming for his help and support.
Contact
List of people currently involved in this initiative:
- Pierre Dragicevic, Inria
- Fanny Chevalier, Inria
- Stéphane Huot, Inria
- Yvonne Jansen, CNRS
- Wesley Willett, University of Calgary
- Charles Perin, City University of London
- Petra Isenberg, Inria
- Tobias Isenberg, Inria
- Jeremy Boy, United Nations Global Pulse
- Enrico Bertini, New-York University
- Lonni Besançon, Inria & LIMSI
- Email us if you wish to contribute!
License
 | All material on this page is CC-BY-SA unless specified otherwise. You can reuse or adapt it provided you link to www.aviz.fr/badstats. |